
Weightless Neural Networks
Weightless Neural Networks are neural networks inspired by the dendritic trees of biological neurons. These weightless networks are primarily comprised of look-up table (LUT) based neurons, and eliminate the need for power and resource hungry multiply-accumulate operations in conventional neurons. A LUT is a highly expressive neuron, as it can inherently learn and represent non-linear functions. Weightless Neural Networks learn these non-linear function representations, aided by approximate gradient definitions for table-entries and indices.
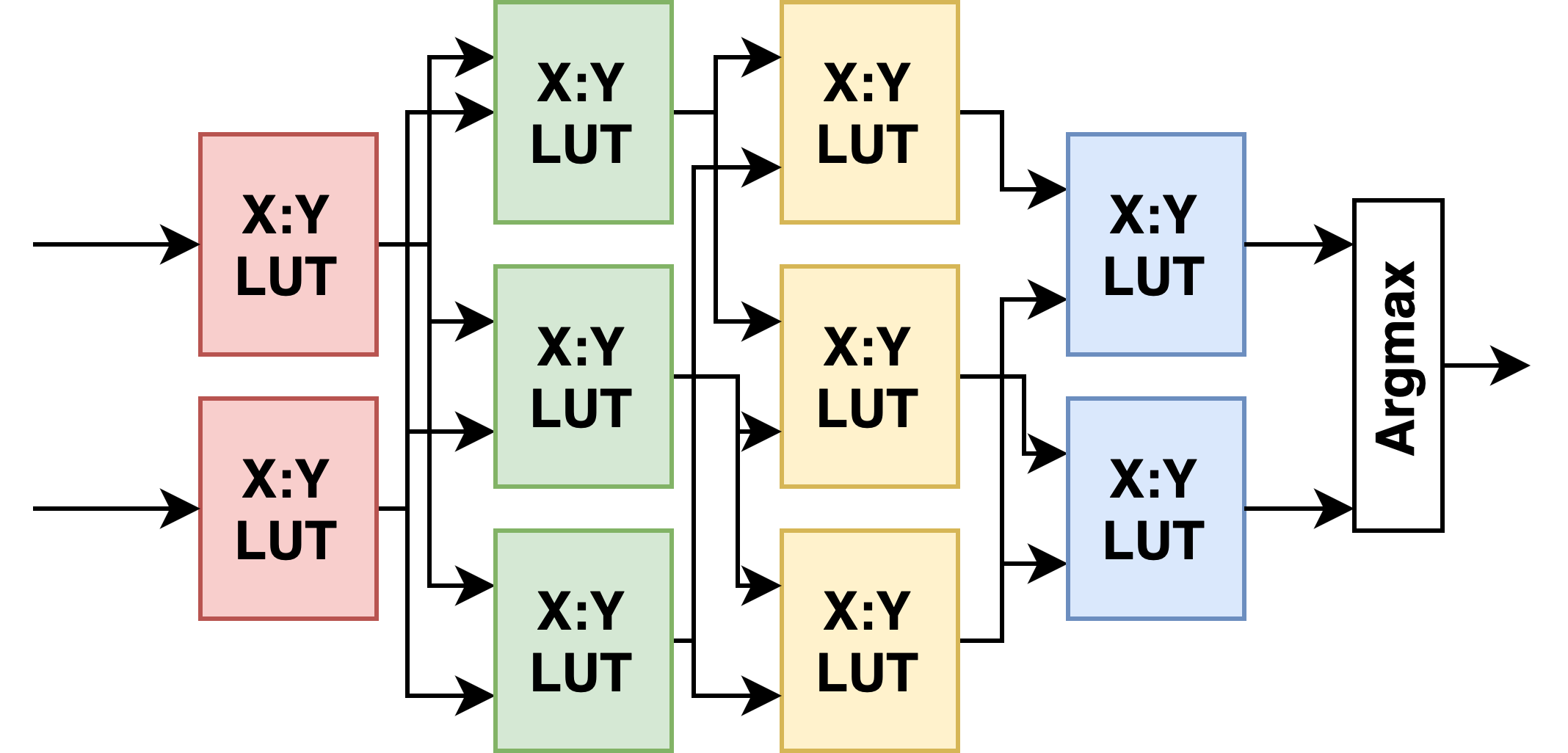
LL-ViT: Edge Deployable Vision Transformers with Look Up Table Neurons
Vision Transformers have been tremendously successful in computer vision tasks. However, their large computational, memory, and energy demands are a challenge for edge inference on FPGAs – a field that has seen a recent surge in demand. We recognize the benefits of recent works on logic and Look Up Table (LUT) based networks, such as LogicNets, NeuraLUT, DWN, among others, in offering models that simultaneously reduce both the memory and compute footprints. However, these models natively do not perform well on common vision tasks, such as CIFAR-10/100. In this work, we propose LL-ViT, a novel edge optimized vision transformer design that integrates layers of LUT neurons within the transformer architecture. Based on our characterization that reveals that a majority of model weights and computations are from the channel mixer (MLP layer), we design an alternate LUT-based channel mixer, and simultaneously develop an FPGA-based accelerator for LL-ViT. Contrary to some attempts to replace each multiplication with a table lookup, our architecture utilizes a neural learning approach which natively learns the LUT functions. This approach allows for reduced model sizes, and a computational and energy-efficient inference solution for vision transformer models. Evaluating on edge-suitable workloads, we achieve accuracies of 95.5% on CIFAR-10, 78.8% on CIFAR-100, and 60.9% on Tiny-ImageNet datasets, comparable to the baseline transformer. LL-ViT eliminates over 60% of the model weights and 50% of the multiplications in the model, and achieves 1.9x energy efficiency and 1.3x lower latency over an integer quantized ViT accelerator, while also offering superior throughput against prior works at a 10.9W power budget. Vision Transformer models, such as ViT, Swin Transformer, and Transformer-in-Transformer, have recently gained significant traction in computer vision tasks due to their superior performance and scalability. Several applications such as drone navigation require real-time inference of these models on the edge. However, these models are quite large and compute-heavy, making them difficult to deploy in resource-constrained edge devices.
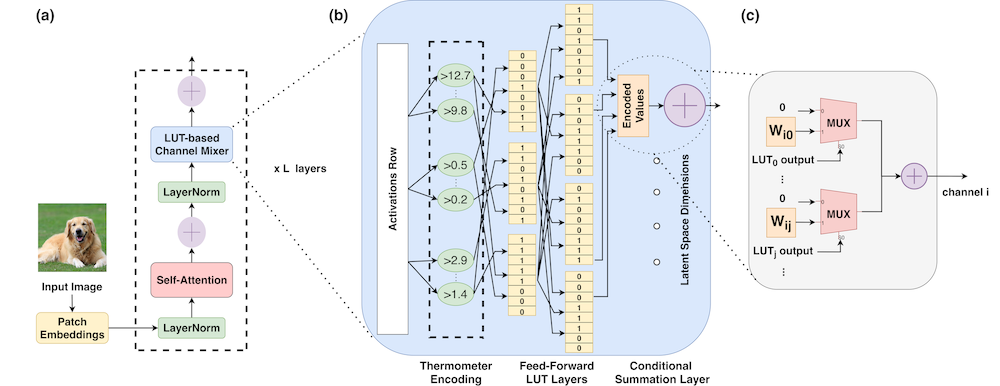
LL-ViT model design
Read the complete paper here